




The World of Serverless Applications
A serverless architecture allows software developers to create and launch applications without worrying about infrastructure support, fault-tolerance, scalability, and capacity provisioning. It has been around for some years, and as people adopt the technology, several articles have been written about how good Lambda functions are, what you should be worried about, and the disadvantages of having an architecture where you don’t have full control of.
Here, we’ll summarize and give in-depth technical answers to many of the questions and debating points about Lambda functions that have been around the internet since the birth of serverless applications.
The Good
When you start working with AWS Lambda functions, the first thing that you notice is how easy it is to have your code ready for production. As you have the code fully running on the AWS infrastructure, you’ll spend less time worrying about how the application will be deployed and instead focus entirely on the business logic of the solution. Taking the burden of managing the infrastructure from the developers is much appreciated. Also, as you can access the configuration that your container will have when the Lambda function gets executed, you can quickly adjust it without doing a deployment.
Just after the Lambda function gets executed, AWS will create a new instance of a container under the hood, which will die ten to fifteen minutes after your Lambda function finishes. In a Serverless architecture, you’ll only pay for the resources you use, and as Lambda functions don’t have any idle cost, hosting your infrastructure in the cloud will make you save up to 90% in server costs.
Imagine that your application goes viral overnight and you go from a thousand users to fifty thousand. If you are managing your own servers, you know this is a recipe for disaster.
During these peak times, your business needs to handle the spike of requests without any downtime or delay, and this is where AWS Lambda functions can save the day. The AWS Lambda service scales automatically with demand, creating multiple containers (or re-using them) to serve all requests.
As your user base grows, you’ll start to notice more Lambda invocations than before, but you won’t have to make any change to the configuration to support a new load of users as Lambda will handle all of it.
By using AWS Step Functions, you have the possibility to build complex asynchronous workflows to perform different tasks. Step Function workflows, or just workflows, give developers the option of chaining several AWS Lambdas where each of them performs a small task and then passes its responses to the next one. This allows the creation of small and testable Lambdas that can be reused across several workflows. We can make an entire solution using only Lambda functions, and we can also make use of it’s great integration with other AWS services—S3, Kinesis, DynamoDB, among many others—as Lambda is an event-driven architecture.
The Bad
If I told you that using AWS Lambda functions will make you save money, prevent you from worrying about infrastructure, and give developers the possibility of focusing on what’s important, you’ll probably be waiting for a cold shower of reality because everyone would be using a serverless architecture if it were all advantages. Let’s discuss the most common topics of debate that make people reject switching to a serverless architecture.
If you were to search over the internet “issues of using AWS Lambda”, the first result that will show up are cold starts. It isn’t a strange concept, the first request that is made to a Lambda function will have a higher response time than the following one. This can add significant overhead—up to 1.5s of latency!
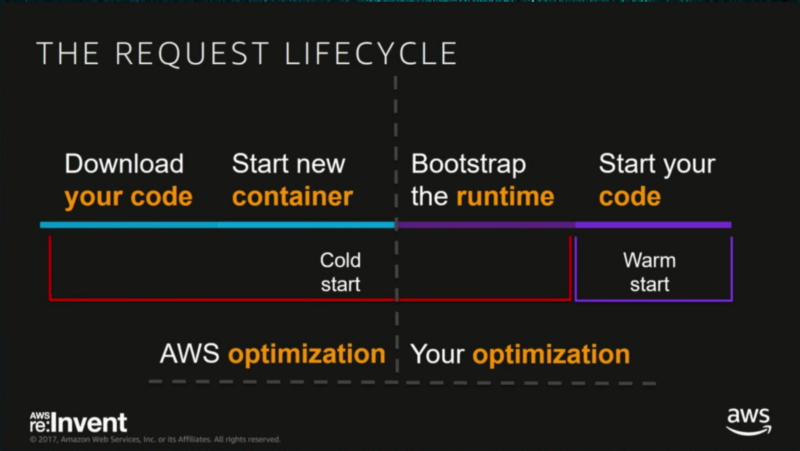
Having cold starts on the first response from your API could or could not affect your business. Most of the time, this isn’t a dealbreaker for adopting a serverless approach as multiple solutions have emerged that prevent or solve this issue.
You should be worried about cold starts on Lambdas only in these scenarios:
- You have a Lambda function that isn’t executed very often and it should respond in the fastest possible way when a request is made.
- You have a front-facing Lambda function to end users that should always have the fastest response time.
As said previously, multiple solutions and tips have emerged to solve this limitation or issue in Lambdas. The main considerations when working with Lambda functions and minimizing cold starts are:
- Avoid setting up a Virtual Private Cloud for your Lambda function as much as possible: Amazon Virtual Private Cloud (Amazon VPC) lets you launch AWS resources into your defined network, resembling a traditional one regarding dynamics, but with the benefits of a professional cloud service. However, when you create a VPC for your Lambda function and execute your code, not only will you have to wait for the container creation, but you’ll also need to wait until the Elastic Network Interfaces (ENIs) are created and attached to your Lambda.
- Avoid using statically typed languages for your Lambda functions (Java and C#) as they have over 100 times higher cold start time. It is recommended to use Python or Node to reduce the latency added by cold starts.
- Use a higher memory size for your Lambda function to decrease the latency by cold starts linearly.
These could mean limitations for your application. For example, if your Lambda function needs to access a resource on the internet, you’ll need to set up a VPC for it, and there is no workaround for that. If this Lambda function is user-facing, you’ll most definitely experiment higher response times. Luckily, engineers have proposed and implemented solutions for this issue.
There are two main approaches to keep your Lambda function warm, and both of them have their advantages and disadvantages:
1) Use AWS Provisioned Concurrency: launched in December 2019, it’s the AWS proposed solution to overcome cold starts on Lambda. Provisioned Concurrency will ensure that your Lambda function has always an instantiated container and therefore you’ll never experience cold starts. It’s pretty simple to configure and does the job, but it kind of goes against the whole serverless experience of “running your code on demand”. Another thing to keep in mind is that this solution isn’t the most cost-efficient one and should only be considered for applications that run 24/7 and cannot experience cold starts at all.
2) Create a warm up module: This was the approach taken by AWS developers before Provisioned Concurrency was launched. Here, developers would create a minimum logic on the handler of the Lambda function that wouldn’t make any operation and execute it on demand (using AWS Cloudwatch rules). Using this approach, developers could configure different times to keep the Lambda warm, and reduce the costs of always having the Lambda available. For example, if you were a food providing application, you’ll probably only need your Lambda to have the minimum latency times during peak hours.
That’s enough of cold starts. We’ve seen how they affect Lambda functions, how to minimize them, and how to prevent them. Now let’s talk about another potential risk that Lambda functions have: Timeouts.
Lambda functions have a timeout parameter after which the Lambda runtime finishes the execution. It can happen at any point, and that might be while it’s executing part of its logic.
Imagine that we’re downloading an S3 file and then storing it’s metadata over DynamoDB and, while the download is being processed, the execution gets terminated. This could occur when the S3 file is too large, the S3 service is experiencing higher response times, or in the middle of the DynamoDB write, and it could make your application inconsistent.
With this information, you’ll probably be tempted to set the maximum timeout for your Lambda (15 minutes), but that isn’t how Lambda functions are supposed to work. In the moment of setting up a timeout for your Lambda, you’ll need to consider which is the event source that executes it. If, for example, you execute the Lambda function over an AWS API Gateway, the API Gateway will run out of time after 30 seconds, and it is a hard limit.

This means that even if your function can run for fifteen minutes, the API Gateway would have timed out and returned a 500 error to the caller.
Consider using AWS Fargate instead of AWS Lambda for tasks that take more than 30 seconds to complete even if you won’t have API Gateway as your event source. If your task will take many hours, consider Elastic Beanstalk or EC2.
If your Lambda function is doing too many things at once, and the response time is averaging more than 3-6 seconds, you should consider using AWS Step Functions and breaking up the function, then delegating retry logic to Step Functions.
The Ugly
Now let’s talk about the core issue of Lambda functions and why they shouldn’t be used in every application. We mentioned how Lambda functions scale on demand, and how you’ll never be worried about the infrastructure as everything will be delegated to AWS, but there is a catch to it.
AWS Lambda functions have a limit and a rate on how much they can scale—this is a concept we’ve talked about. When you make a request to a Lambda, you’re essentially spinning up a container that will run your code, and this is when Lambda has its biggest limitation: concurrency.
The concurrency of your lambda function can be defined as how many containers are currently running for it—the number of instances of your lambda function. Lambda can support up from 500-3000 parallel instances serving requests, depending on the region of the initial burst of concurrency. Then, it can serve 500 additional instances each minute until all requests are resolved, it’ll scale down afterwards.
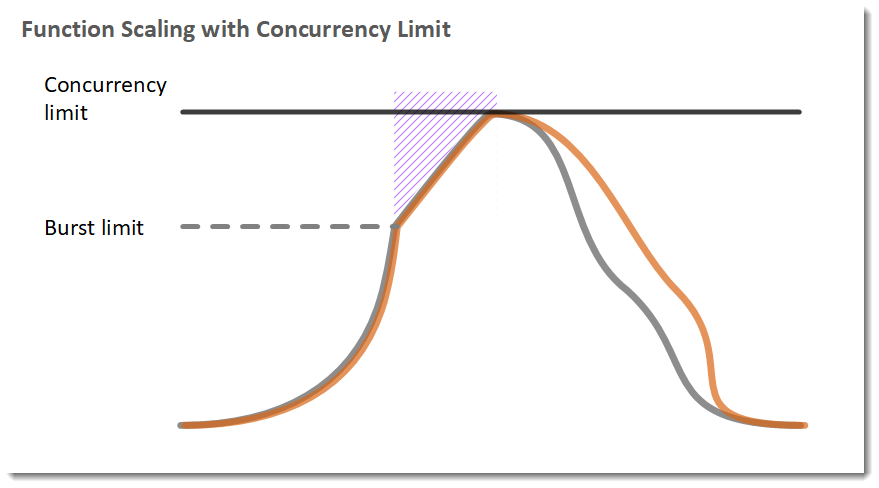
But what happens if we have a huge spike of requests coming in, and we have to continue providing more and more instances each time? This is where the real ugly comes in—there is a hard limit on how many Lambda instances can be running on a region per account.
This limit is calculated as ten times your concurrent executions quota—default is 1000.
If you surpass this limit, your Lambda will begin to throttle and all incoming requests will fail. This can be even more scary when you understand that this limit is per account, and even other Lambda functions that you could have in the region will throttle as well.
Finally, you’ll need to be extra careful when working with Lambda functions and their event sources to never create an infinite loop, or your whole application could present an outage until an alarm is raised and you can figure it out while your entire system is down when the whole objective of serverless was to not to worry about infrastructure.
Explore our

How to Improve MongoDB Query Performance
Here are two key techniques to develop large, scalable, efficient, functional, and incredibly fast databases on your own. ..

What I Learned on December 23, 2020
We felt the satisfaction that comes from knowing that, despite everything that happened during this challenging year, we were there, together. ..

The Challenges of Deploying Real-Time Streaming Platforms
Have you heard the saying, “Whatever you do, do it right”? Doing things right isn’t always easy, but it’s always worth the effort. ..